배열(Array)은 연속된 메모리 공간을 사용하는 자료구조로, 인덱스를 통한 조회 속도는 빠르지만 데이터의 위치를 변경하는 연산에는 상대적으로 많은 비용이 듭니다. 특히 코딩 테스트나 시스템 최적화 과정에서 빈번하게 등장하는 배열 회전(Array Rotation) 문제는 단순해 보이지만, 입력 크기(N)와 회전 횟수(K)가 커질수록 알고리즘의 효율성 차이가 극명하게 드러납니다. 단순한 반복문으로 구현할 경우 시간 복잡도가 급증하여 타임아웃(Time Limit Exceeded)이 발생하기 쉽습니다. 이 글에서는 배열 회전의 비효율적인 접근 방식을 분석하고, 시간 복잡도 O(n)과 공간 복잡도 O(1)을 동시에 달성하는 최적화된 역전 알고리즘(Reversal Algorithm)을 상세히 다룹니다.
1. 배열 회전의 문제 정의와 비효율적 접근
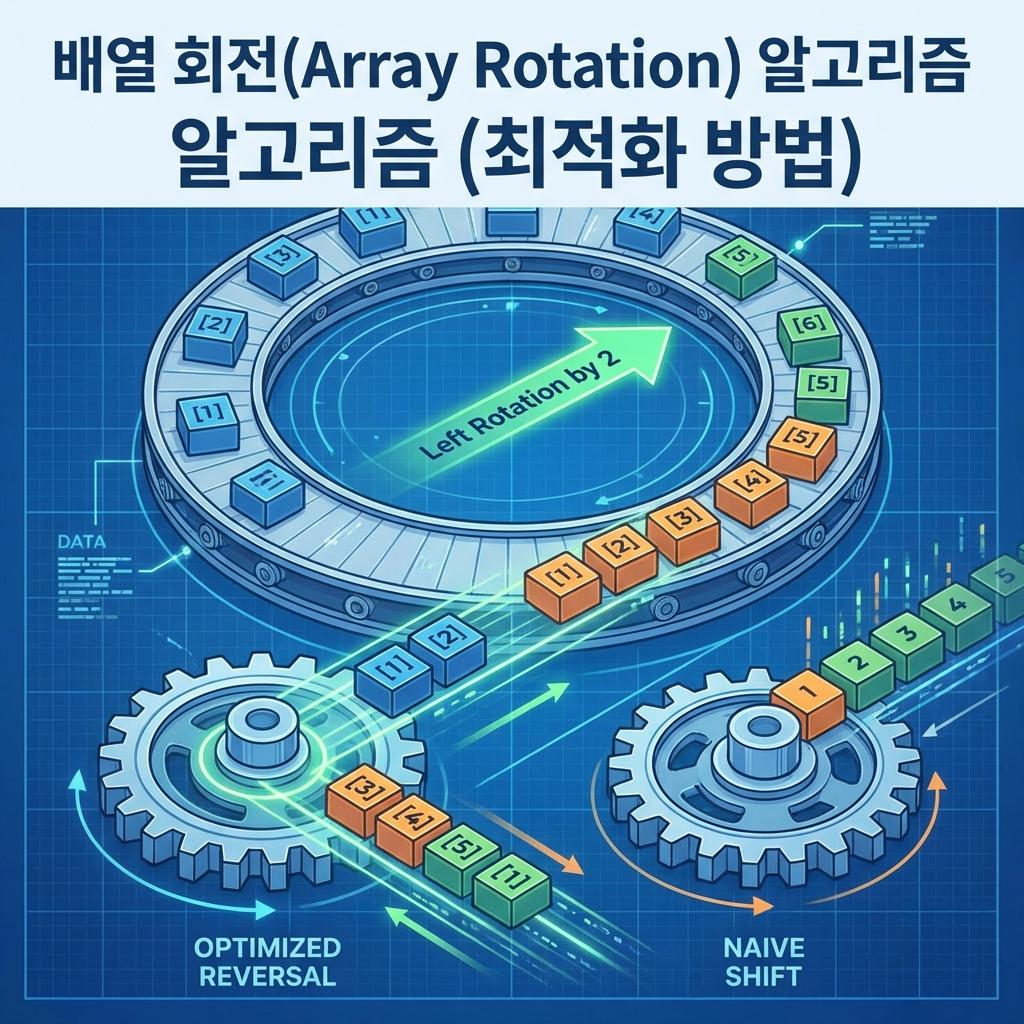
배열 회전이란 배열의 요소들을 왼쪽이나 오른쪽으로 $k$만큼 이동시키고, 범위를 벗어난 요소들을 반대편 빈 공간으로 채워 넣는 연산을 말합니다. 예를 들어 `[1, 2, 3, 4, 5]`를 왼쪽으로 2번 회전시키면 `[3, 4, 5, 1, 2]`가 됩니다.
1-1. 브루트 포스(Brute Force) 방식의 한계
가장 직관적인 방법은 모든 요소를 한 칸씩 이동시키는 작업을 $k$번 반복하는 것입니다.
- 동작: 첫 번째 요소를 임시 변수에 저장하고, 나머지 요소를 왼쪽으로 한 칸씩 당긴 후, 임시 변수 값을 맨 뒤에 넣습니다.
- 문제점: 배열의 크기가 $n$이고 회전 횟수가 $k$일 때, 시간 복잡도는 O(n × k)가 됩니다. 만약 $n$이 10만이고 $k$가 5만이라면, 연산 횟수는 50억 번에 달해 시스템 성능을 심각하게 저하시킵니다.
2. 공간과 시간의 트레이드오프 (추가 메모리 사용)
속도를 높이기 위한 첫 번째 최적화는 임시 배열(Temporary Array)을 사용하는 것입니다. 회전될 크기($k$)만큼의 데이터를 별도의 배열에 저장해두고, 나머지 데이터를 한 번에 이동시킨 뒤 다시 붙이는 방식입니다.
- 장점: 시간 복잡도가 O(n)으로 획기적으로 줄어듭니다.
- 단점: O(n) 또는 O(k)만큼의 추가 메모리 공간이 필요합니다. 메모리 제약이 심한 임베디드 시스템이나 대용량 데이터 처리 환경에서는 부담이 될 수 있습니다.
3. 최적의 솔루션: 역전 알고리즘 (Reversal Algorithm)
추가적인 메모리를 거의 사용하지 않으면서(O(1) 공간 복잡도), 선형 시간(O(n) 시간 복잡도) 안에 배열을 회전시키는 가장 우아한 방법은 '뒤집기(Reverse)'를 활용하는 것입니다. 이 알고리즘은 배열을 세 부분으로 나누어 뒤집는 것만으로 회전 효과를 냅니다.
3-1. 알고리즘 동작 원리 (왼쪽으로 d만큼 회전 시)
배열 `arr`의 크기가 $n$이고, $d$만큼 왼쪽으로 회전시킨다고 가정해 봅시다. 핵심 로직은 다음과 같습니다.
- 1단계: 앞부분 `arr[0...d-1]`을 뒤집습니다. (인덱스 0부터 d-1까지)
- 2단계: 뒷부분 `arr[d...n-1]`을 뒤집습니다. (인덱스 d부터 끝까지)
- 3단계: 배열 전체 `arr[0...n-1]`을 뒤집습니다.
이 3단계의 마법 같은 과정을 거치면 데이터는 정확히 의도한 위치로 이동하게 됩니다. 오른쪽 회전의 경우 3단계의 순서나 범위를 약간만 조정하면 됩니다.
4. 파이썬(Python) 구현 및 코드 분석
다음은 역전 알고리즘을 사용하여 공간 복잡도를 O(1)로 최적화한 파이썬 코드입니다. 파이썬의 슬라이싱(`[:]`)을 사용하면 코드는 짧아지지만 내부적으로 복사본을 생성하여 메모리를 쓰게 되므로, 아래와 같이 인덱스 스왑(Swap) 방식으로 구현하는 것이 진정한 의미의 In-place Algorithm입니다.
def reverse(arr, start, end):
"""
배열의 start부터 end 인덱스까지 요소를 뒤집는 헬퍼 함수
"""
while start < end:
arr[start], arr[end] = arr[end], arr[start]
start += 1
end -= 1
def left_rotate(arr, d):
n = len(arr)
if n == 0: return
# 회전 횟수 최적화: n번 회전하면 원상복귀 되므로 나머지 연산
d = d % n
# 1. 앞부분(0 ~ d-1) 뒤집기
reverse(arr, 0, d-1)
# 2. 뒷부분(d ~ n-1) 뒤집기
reverse(arr, d, n-1)
# 3. 전체 뒤집기
reverse(arr, 0, n-1)
# 테스트
data = [1, 2, 3, 4, 5, 6, 7]
d = 2
print(f"Original: {data}")
left_rotate(data, d)
print(f"Rotated: {data}")
# 결과: [3, 4, 5, 6, 7, 1, 2]
4-1. 코드 핵심 포인트
- 모듈러 연산 (`d % n`): 회전 횟수 $d$가 배열의 크기 $n$보다 클 경우 불필요한 연산을 방지하기 위해 나머지 연산을 수행합니다. 이는 성능 최적화의 기본입니다.
- In-place Swap: 별도의 리스트를 생성하지 않고, `arr[start], arr[end] = arr[end], arr[start]` 구문을 통해 메모리 내부에서 직접 데이터를 교환합니다.
1. 비효율성: 하나씩 이동시키는 방법은 O(n×k)의 시간 복잡도를 가지므로 대용량 데이터에 부적합합니다.
2. 역전 알고리즘: 배열을 분할하여 세 번 뒤집는(Reverse) 방식이 가장 효율적입니다.
3. 성능: 이 방식을 사용하면 시간 복잡도 O(n)과 공간 복잡도 O(1)을 동시에 만족하여 메모리와 속도를 모두 잡을 수 있습니다.