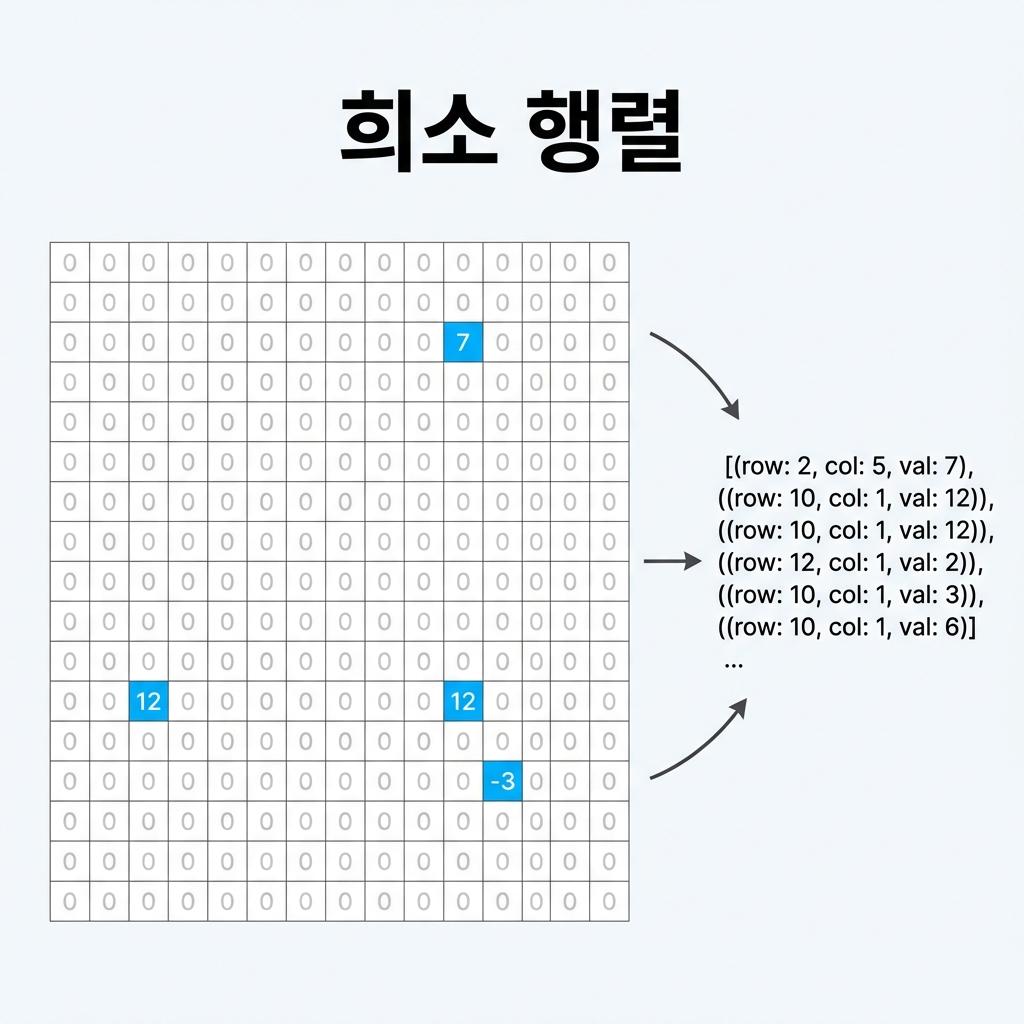
빅데이터 분석과 머신러닝, 특히 자연어 처리(NLP)나 추천 시스템 분야에서 다루는 데이터는 대부분 '0'으로 가득 찬 경우가 많습니다. 예를 들어, 넷플릭스의 수억 명 사용자와 수만 개의 영화 콘텐츠를 행렬로 표현한다면, 한 명의 사용자가 시청한 영화는 극소수일 것이며 나머지 공간은 모두 '시청 안 함(0)'으로 채워질 것입니다. 이처럼 행렬의 원소 중 대다수가 0인 행렬을 희소 행렬(Sparse Matrix)이라고 합니다. 이를 일반적인 2차원 배열로 저장하면 막대한 메모리 낭비와 연산 비효율을 초래합니다. 이 글에서는 희소 행렬의 개념과 이를 효율적으로 저장하기 위한 COO, CSR 형식의 기술적 원리를 심층 분석합니다.
1. 희소 행렬(Sparse Matrix) vs 밀집 행렬(Dense Matrix)
행렬은 0이 아닌 유효 데이터의 비율에 따라 크게 두 가지로 구분됩니다. 이 둘의 차이를 이해하는 것이 메모리 최적화의 첫걸음입니다.
1-1. 밀집 행렬 (Dense Matrix)
우리가 흔히 사용하는 `int[][]` 또는 `numpy.array` 형태입니다. 0을 포함한 모든 데이터를 메모리에 할당합니다. 유효 데이터가 꽉 차 있는 이미지 처리 등의 분야에서는 효율적이지만, 희소 데이터 환경에서는 치명적인 비효율을 낳습니다.
1-2. 희소 행렬의 문제점: 메모리 낭비
가로, 세로가 각각 10만인 행렬($100,000 \times 100,000$)을 가정해 봅시다. 이 행렬을 저장하기 위해 `double`형(8바이트)을 사용한다면, 필요한 메모리는 무려 80GB($10^{10} \times 8$ bytes)에 달합니다. 하지만 이 중 99%가 0이라면, 실제 필요한 데이터는 800MB 수준에 불과합니다. 희소 행렬 자료구조는 이러한 메모리 낭비를 해결하기 위해 고안되었습니다.
2. 효율적인 저장 방식: COO와 CSR
희소 행렬은 0을 저장하지 않고, '0이 아닌 값(Non-zero Value)'과 '그 위치(Index)'만을 저장하는 방식을 사용합니다. 대표적으로 COO와 CSR 방식이 있습니다.
2-1. COO (Coordinate List) 형식
가장 직관적인 방법으로, (행, 열, 값)의 튜플 형태로 데이터를 저장합니다. 파이썬의 딕셔너리나 데이터베이스 테이블 구조와 유사합니다.
- 구조: `row_indices`, `col_indices`, `values` 세 개의 배열을 사용합니다.
- 장점: 데이터 구조가 단순하여 행렬을 처음 생성하거나 구성할 때 매우 빠릅니다.
- 단점: 특정 행을 조회하거나 행렬 연산(곱셈 등)을 수행할 때, 행 인덱스가 정렬되어 있지 않다면 전체를 탐색해야 하므로 비효율적입니다.
2-2. CSR (Compressed Sparse Row) 형식
COO 방식의 메모리 사용량을 더 줄이고, 행(Row) 단위의 연산 속도를 획기적으로 높인 방식입니다. 대부분의 선형 대수 라이브러리(SciPy, TensorFlow 등)에서 표준으로 사용합니다.
CSR은 다음 세 가지 배열로 구성됩니다.
- Values: 0이 아닌 원소들의 값을 차례대로 저장한 배열.
- Column Indices: `Values` 배열의 각 원소가 속한 열 번호.
- Row Pointer (핵심): 각 행이 시작되는 `Values` 배열의 인덱스(Offset)를 저장합니다. 크기는 `(행의 개수 + 1)`입니다.
CSR은 행 단위 접근(Row Slicing)과 행렬-벡터 곱셈(Matrix-Vector Multiplication) 연산에서 압도적인 성능을 자랑합니다.
3. 파이썬(Python) SciPy를 이용한 구현 및 성능 비교
이론을 실제 코드로 확인해 보겠습니다. `scipy.sparse` 라이브러리를 사용하면 밀집 행렬을 희소 행렬로 변환하고 메모리 차이를 직관적으로 확인할 수 있습니다.
import numpy as np
from scipy.sparse import csr_matrix
import sys
# 1. 0이 많은 밀집 행렬 생성 (Dense)
# 1000x1000 행렬, 대부분 0
dense_mat = np.array([
[0, 0, 3, 0],
[1, 0, 0, 0],
[0, 0, 0, 0],
[0, 2, 0, 0]
])
# 2. CSR 형식의 희소 행렬로 변환 (Sparse)
sparse_mat = csr_matrix(dense_mat)
print("=== 데이터 구조 비교 ===")
print(f"Original (Dense):\n{dense_mat}")
print(f"\nCSR Values: {sparse_mat.data}")
print(f"CSR Column Indices: {sparse_mat.indices}")
print(f"CSR Row Pointer: {sparse_mat.indptr}")
# 3. 메모리 효율성 (가상의 대형 데이터 가정 시)
# 실제 대형 데이터에서는 sparse_mat.data.nbytes가
# dense_mat.nbytes보다 수백 배 작아집니다.
3-1. 코드 실행 결과 분석
위 코드에서 `sparse_mat.indptr` (Row Pointer)이 `[0, 1, 2, 2, 3]`으로 출력됩니다. 이는 0행은 인덱스 0~1, 1행은 인덱스 1~2, 2행은 데이터 없음(2~2), 3행은 2~3 구간의 데이터를 가진다는 의미입니다. 이처럼 압축된 인덱싱을 통해 메모리와 탐색 시간을 동시에 절약합니다.
1. 필요성: 데이터의 대부분이 0인 경우, 일반 배열을 사용하면 심각한 메모리 낭비가 발생합니다.
2. 해결책: CSR(Compressed Sparse Row) 형식은 0이 아닌 값과 위치 정보만 저장하여 메모리 사용량을 최소화합니다.
3. 활용: 추천 시스템, 그래프 알고리즘, 자연어 처리 등 대규모 데이터 연산의 필수 자료구조입니다.