프로그래밍과 컴퓨터 공학에서 자료구조(Data Structure)에 대한 이해는 효율적인 알고리즘 설계의 핵심입니다. 특히 배열(Array)의 고정된 크기와 메모리 낭비 문제를 해결하기 위해 등장한 연결 리스트(Linked List)는 동적 메모리 할당의 기초가 되는 매우 중요한 개념입니다. 많은 개발자가 이론적으로는 알고 있지만, 실제 현업에서 단일 연결 리스트와 이중 연결 리스트의 정확한 차이와 구현 시의 장단점을 명확히 구분하지 못하는 경우가 있습니다. 이 글에서는 연결 리스트의 핵심 원리를 분석하고, 단일(Singly)과 이중(Doubly) 구조의 차이점을 기술적으로 상세히 다루어 보겠습니다.
1. 연결 리스트(Linked List)의 핵심 개념과 배열과의 차이
연결 리스트는 데이터 요소들을 메모리의 연속된 공간에 배치하지 않고, 임의의 위치에 저장한 뒤 이를 포인터(Pointer)로 연결하여 관리하는 선형 자료구조입니다. 배열이 인덱스(Index)를 통한 빠른 접근(Random Access)에 최적화되어 있다면, 연결 리스트는 데이터의 삽입과 삭제에 최적화되어 있습니다.
1-1. 노드(Node)의 구조
연결 리스트의 가장 기본 단위는 노드입니다. 하나의 노드는 데이터를 저장하는 데이터 필드(Data Field)와 다음 노드의 주소를 가리키는 링크 필드(Link Field)로 구성됩니다.
- 데이터(Data): 실제로 저장하고자 하는 값 (정수, 구조체, 객체 등).
- 포인터(Next/Prev): 다음 노드(또는 이전 노드)의 메모리 주소를 저장하는 변수.
1-2. 시간 복잡도(Time Complexity) 비교
자료구조 선택 시 가장 중요한 기준은 시간 복잡도입니다. 배열과 연결 리스트는 상반된 특성을 가집니다.
- 접근(Access): 배열은 O(1)이지만, 연결 리스트는 순차적으로 탐색해야 하므로 O(n)이 소요됩니다.
- 삽입/삭제(Insertion/Deletion): 배열은 요소를 이동시켜야 하므로 O(n)이 걸리지만, 연결 리스트는 포인터만 변경하면 되므로 위치를 알고 있다는 가정하에 O(1)의 성능을 보입니다.
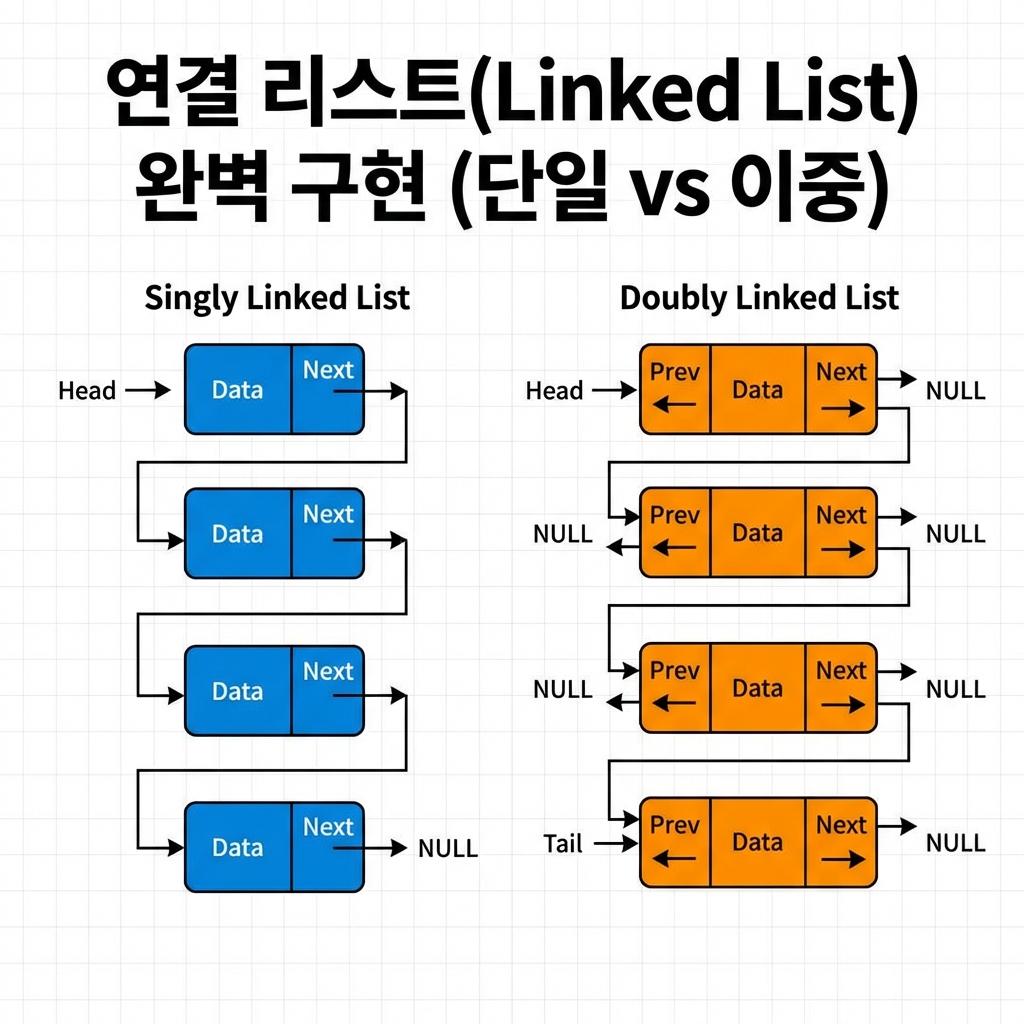
2. 단일 연결 리스트 (Singly Linked List) 심층 분석
단일 연결 리스트는 각 노드가 다음 노드(Next)에 대한 참조만을 가지는 가장 단순한 형태입니다. 마지막 노드의 포인터는 NULL(또는 None)을 가리켜 리스트의 끝을 나타냅니다.
2-1. 구조적 특징 및 장단점
단일 연결 리스트는 구현이 간단하고, 각 노드당 하나의 포인터만 저장하면 되므로 메모리 공간 효율성이 이중 연결 리스트보다 높습니다. 하지만 탐색 방향이 단방향(Head → Tail)으로 고정되어 있어, 특정 노드의 바로 이전 노드에 접근하려면 처음부터 다시 탐색해야 한다는 단점이 있습니다. 이는 역방향 탐색이 불가능함을 의미하며, 데이터 복구 로직 구현 시 취약점이 될 수 있습니다.
3. 이중 연결 리스트 (Doubly Linked List) 심층 분석
이중 연결 리스트는 단일 연결 리스트의 탐색 제약을 해결하기 위해 고안되었습니다. 각 노드는 두 개의 포인터, 즉 이전 노드(Prev)와 다음 노드(Next)를 모두 가리킵니다.
3-1. 양방향 탐색의 이점
이 구조의 가장 큰 장점은 양방향 탐색(Bidirectional Traversal)이 가능하다는 점입니다. 따라서 탐색 도중 문제가 발생하거나 특정 인덱스에서 앞뒤 데이터를 참조해야 하는 알고리즘(예: 브라우저의 뒤로 가기/앞으로 가기, 편집기의 Undo/Redo) 구현에 매우 적합합니다.
3-2. 구현의 복잡성과 메모리 오버헤드
기능이 강력한 만큼 비용이 따릅니다. 각 노드마다 포인터 변수가 하나 더 필요하므로 단일 연결 리스트에 비해 메모리 사용량이 증가합니다. 또한, 데이터를 삽입하거나 삭제할 때 Prev와 Next 포인터를 모두 갱신해야 하므로 구현 로직이 복잡해지며, 실수할 경우 참조 무결성이 깨질 위험이 높습니다.
4. 기술적 구현 예시 (Python Code)
이론을 실제 코드로 구현해보는 것은 이해도를 높이는 가장 좋은 방법입니다. 다음은 Python을 이용한 단일 연결 리스트의 기본적인 노드 정의와 추가(Append) 기능 구현 예시입니다.
class Node:
def __init__(self, data):
self.data = data
self.next = None # 다음 노드를 가리키는 포인터
class SinglyLinkedList:
def __init__(self):
self.head = None
def append(self, data):
new_node = Node(data)
# 리스트가 비어있을 경우
if not self.head:
self.head = new_node
return
# 마지막 노드까지 탐색
current = self.head
while current.next:
current = current.next
# 마지막 노드에 새 노드 연결
current.next = new_node
# 사용 예시
s_list = SinglyLinkedList()
s_list.append(10)
s_list.append(20)
위 코드에서 볼 수 있듯이, append 메서드는 current.next가 존재하지 않을 때까지 순회한 후 새로운 노드를 연결합니다. 이중 연결 리스트라면 new_node.prev = current 코드가 추가되어야 합니다.
1. 구조적 차이: 단일 연결 리스트는 단방향(Next), 이중 연결 리스트는 양방향(Next, Prev) 포인터를 가집니다.
2. 선택 기준: 메모리 절약과 단순 구현이 목표라면 단일, 탐색 유연성과 양방향 이동이 필요하다면 이중 연결 리스트를 선택합니다.
3. 성능 특성: 데이터의 빈번한 삽입/삭제가 발생하는 로직에 유리하며, 검색 위주의 로직에는 배열이 더 적합합니다.