관계형 데이터베이스(RDBMS)에서 수백만 건의 데이터 중 원하는 정보를 1초 미만의 짧은 시간에 찾아낼 수 있는 비결은 바로 인덱스(Index)에 있습니다. 그리고 이 인덱스를 구현하는 가장 핵심적인 알고리즘이 바로 B-Tree와 그 확장형인 B+Tree입니다. 대용량 데이터를 처리할 때 이진 탐색 트리(BST)는 트리의 높이가 너무 높아져 디스크 I/O 비용이 폭증하는 문제가 있지만, B-Tree 계열은 노드 하나에 여러 데이터를 담음으로써 트리의 높이를 획기적으로 낮춥니다. 이 글에서는 현대 데이터베이스 시스템이 왜 단순한 B-Tree가 아닌 B+Tree를 기본 인덱스 구조로 채택하는지, 그 기술적 차이점과 성능상의 이점을 심층 분석합니다.
1. B-Tree: 균형 잡힌 다진 검색 트리
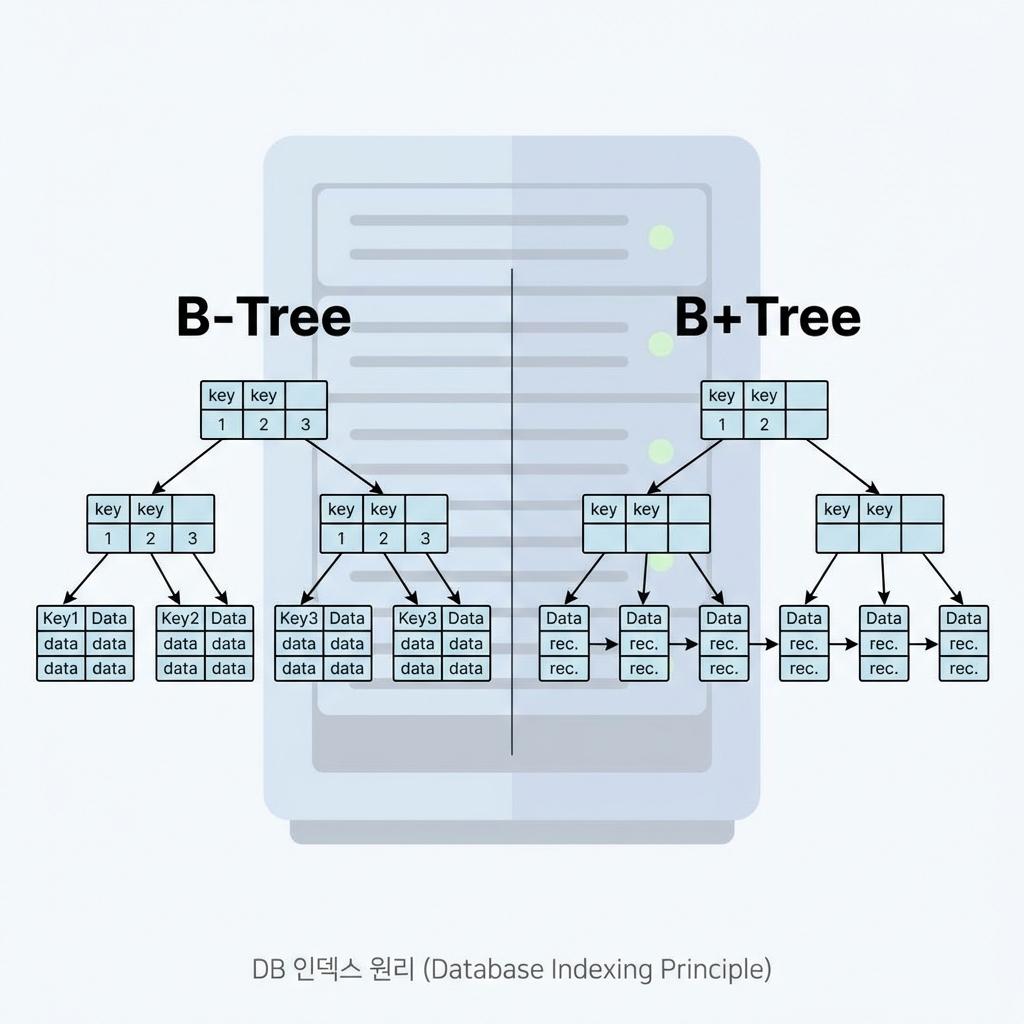
B-Tree는 모든 리프 노드가 같은 레벨에 있도록 유지하는 자가 균형 트리(Self-Balancing Tree)입니다. 이진 트리와 달리 노드 하나가 가질 수 있는 자식 노드의 개수가 2개 이상(M개)인 것이 특징입니다.
1-1. 주요 특징
- 데이터 위치: 모든 노드(루트, 중간, 리프)가 데이터(Value)를 직접 가질 수 있습니다.
- 검색 효율: 운 좋게 루트 노드나 중간 노드에서 원하는 데이터를 찾으면 탐색을 즉시 종료할 수 있어 평균 검색 시간이 매우 빠릅니다.
- 중복 제거: 키(Key) 값이 트리 전체에서 유일하게 존재하므로 데이터 중복 저장의 우려가 없습니다.
2. B+Tree: DB 인덱스에 최적화된 진화형
B+Tree는 B-Tree의 구조를 개선하여 대량의 데이터를 스캔(Scan)하거나 범위 검색(Range Query)을 수행할 때 압도적인 성능을 발휘하도록 설계된 자료구조입니다. MySQL의 InnoDB를 포함한 대부분의 상용 DB가 이 방식을 사용합니다.
2-1. B-Tree와의 결정적 차이점
- 데이터의 분리: 오직 리프 노드(Leaf Node)에만 실제 데이터(Value)가 저장됩니다. 중간 노드(Internal Node)들은 경로를 안내하는 인덱스(Key) 역할만 수행합니다.
- 연결 리스트(Linked List): 모든 리프 노드들이 포인터로 서로 연결되어 있습니다. 이 덕분에
WHERE age BETWEEN 20 AND 30과 같은 범위 검색 시 트리를 다시 올라갔다 내려올 필요 없이 리프 노드만 순차적으로 읽으면 됩니다. - 더 높은 차수: 중간 노드에 실제 데이터가 없기 때문에, 하나의 노드(페이지)에 더 많은 인덱스 키를 담을 수 있습니다. 이는 트리의 높이를 더 낮추어 디스크 I/O 횟수를 최소화합니다.
3. 기술적 비교 분석
두 자료구조의 차이를 한눈에 파악할 수 있도록 표로 정리했습니다.
| 비교 항목 | B-Tree | B+Tree |
|---|---|---|
| 데이터 저장 | 모든 노드에 저장 가능 | 오직 리프 노드에만 저장 |
| 리프 노드 연결 | 연결되지 않음 | Linked List로 연결됨 |
| 범위 탐색 | 전체 트리 순회 필요 (비효율) | 리프 노드 스캔 (매우 효율적) |
| 높이 (Height) | 상대적으로 높음 | 더 낮음 (한 노드에 더 많은 키 저장) |
4. 왜 B+Tree가 DB 인덱스의 표준인가?
데이터베이스의 성능 병목 현상은 대부분 메모리가 아닌 디스크 I/O에서 발생합니다. B+Tree는 다음과 같은 이유로 디스크 기반 저장 시스템에 최적화되어 있습니다.
4-1. 캐시 히트율(Cache Hit Rate) 상승
중간 노드의 크기가 작기 때문에 메모리(Buffer Pool)에 더 많은 인덱스 노드를 올릴 수 있습니다. 이는 원하는 데이터를 찾기 위해 디스크까지 내려가야 하는 횟수를 획기적으로 줄여줍니다.
4-2. 풀 스캔(Full Scan) 효율성
데이터베이스에서 모든 레코드를 읽어야 하는 작업 시, B-Tree는 트리의 모든 노드를 방문해야 하지만 B+Tree는 리프 노드의 연결 리스트만 한 번 쭉 읽으면 끝납니다. 이는 선형 탐색과 같은 속도를 보장합니다.
1. 차이: B-Tree는 모든 노드에 데이터를 저장하지만, B+Tree는 리프 노드에만 데이터를 저장하고 리프끼리 연결합니다.
2. 장점: B+Tree는 범위 검색에 탁월하며, 트리의 높이가 낮아 디스크 접근 횟수를 최소화합니다.
3. 실무: 검색 속도가 중요한 소규모 데이터는 B-Tree가 유리할 수 있으나, 대규모 DB 시스템에서는 안정적인 스캔 성능을 제공하는 B+Tree가 표준입니다.